Introduction
Most enterprise AI failures today are not model failures — they are context failures. When powerful large language models produce wrong or hallucinated outputs, the root cause typically lies not in the model's capabilities but in the information it received. A 2025 MIT study analyzing 300 AI deployments found that 95% of generative AI pilots fail to achieve rapid revenue acceleration, while McKinsey reported that fewer than 25% of companies experimenting with AI agents reach production.
The gap comes down to a fundamental misunderstanding of how LLMs work. These are text-completion engines that predict the next token based on input sequences — nothing more. If the input lacks the right information, is cluttered with irrelevant data, or buries critical facts where attention degrades, no amount of model sophistication can compensate.
Context engineering is the discipline that addresses this directly: designing systems that select, structure, and deliver the right information to an LLM at the right time.
This guide covers what context engineering is, how it differs from prompt engineering, its four core pillars, practical implementation techniques, and measurable business benefits for enterprise AI applications.
TLDR
- Context engineering designs dynamic systems that deliver the right information, tools, and instructions to LLMs at runtime
- It directly addresses context failures, the primary cause behind 95% of enterprise AI pilot failures
- Four pillars structure any context engineering effort: Instructions, Memory, Knowledge Retrieval, and Tools
- Hybrid RAG with reranking delivers 39% better retrieval than vector search alone
- Context compaction reduces token usage by 50% while maintaining accuracy in long-running workflows
What Is Context Engineering in AI?
Context engineering is the practice of designing dynamic systems that select, structure, and deliver the right information, tools, and instructions to an LLM at the right time — going well beyond the single prompt a user types. Anthropic formally defined context engineering in September 2025 as "optimizing the utility of tokens against the inherent constraints of LLMs in order to consistently achieve a desired outcome."
Prompting an LLM is like handing a new employee a sticky note with instructions. Context engineering is like providing a full briefing — complete with relevant documents, historical decisions, tool access, and clear operating procedures.
What Makes Up "Context"?
"Context" is everything the model sees before generating a response:
- System instructions defining role and constraints
- Session history from the current conversation
- Retrieved documents or database records
- Tool definitions and function schemas
- Prior outputs from previous reasoning steps
- User's current message
Andrej Karpathy described context engineering as "the delicate art and science of filling the context window with just the right information for the next step." Under-fill it with the wrong information and the model underperforms. Overfill it with irrelevant content and costs climb while quality degrades.
The Context Window Challenge
Models have finite attention budgets measured in tokens. Modern systems like Claude Sonnet 4.6 offer 1 million-token windows, but size isn't the solution. Chroma's July 2025 study of 18 LLMs documented "context rot" — performance becomes increasingly unreliable as input length grows. The 10,000th token is not processed as reliably as the 100th.
The study's key findings have direct implications for enterprise RAG systems:
- Models performed dramatically better on focused ~300-token prompts than full ~113,000-token prompts
- Topically related but incorrect content (distractors) degraded performance more than completely irrelevant content
- Reliability dropped non-linearly — the drop-off accelerated beyond certain context thresholds
The Principle of Minimum Viable Context
Context rot makes the case for restraint over abundance. Neo4j's Michael Hunger introduced the Minimum Viable Context (MVC) principle: the goal is not to stuff the context window with everything available — it is to provide the smallest, highest-signal set of information that enables the model to complete the current step accurately and reliably.
MVC shifts thinking from "how much can we include?" to "what is essential right now?" The result: lower token costs, less context rot, and more consistent model output.
Context Engineering vs. Prompt Engineering: Key Differences
Prompt engineering and context engineering solve different problems. Knowing when to use each — or combine them — determines whether your AI system guesses or actually knows.
| Dimension | Prompt Engineering | Context Engineering |
|---|---|---|
| Focus | How to phrase instructions | What the model knows before answering |
| Scope | Static textual instructions | Dynamic information pipelines |
| Complexity | Short task descriptions | Retrieval systems, memory stores, state management |
| Key Question | "How do I phrase this?" | "What context configuration generates desired behavior?" |

The table above shows the structural gap. The practical question is when each approach is actually sufficient.
When Each Approach Is Sufficient
Use prompt engineering alone for:
- Narrow, single-source tasks with static requirements
- One-off text transformations
- Simple classification or summarization
- Tasks where all necessary information fits in the user's message
Use context engineering for:
- Multi-step workflows requiring state persistence
- Time-sensitive data that changes between requests
- Access-controlled information from multiple sources
- Any scenario where the model must cite evidence
A Concrete Scenario
Consider a customer support AI:
Prompt engineering only: The system has a well-crafted system prompt defining tone, response format, and general policies. When a customer asks about their order, the AI guesses based on training data and makes generic suggestions.
Context engineering: Before responding, the system:
- Retrieves the customer's order history from the database
- Pulls open support tickets
- Fetches applicable SLA policy based on account tier
- Loads relevant product documentation
The second produces grounded, actionable answers. The first produces plausible-sounding ones that may be entirely wrong.
As Karpathy noted: "People's use of 'prompt' tends to (incorrectly) trivialize a rather complex component. You prompt an LLM to tell you why the sky is blue. But apps build contexts (meticulously) for LLMs to solve their custom tasks."
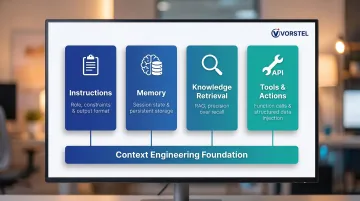
The Four Pillars of Context Engineering
These four pillars provide a practical framework for structuring any context engineering effort. Every reliable AI agent needs all four.
Pillar 1: Instructions
Instructions define the model's role, objectives, constraints, safety rules, and output format. Effective instructions are specific enough to shape behavior without hardcoding every edge case.
Best practices:
- Organize instructions into labeled sections (Background, Task, Rules, Output Format)
- Start with minimal prompts and expand based on observed failures
- Avoid brittle logic that breaks on unexpected inputs
- Use clear formatting (XML tags, markdown headers) to delineate sections
Example structure:
## Role
You are a financial compliance assistant for enterprise clients.
## Task
Review transaction records and flag potential regulatory violations.
## Rules
- Only flag transactions exceeding policy thresholds
- Always cite the specific policy section violated
- Never approve transactions without complete data
## Output Format
Return JSON with: {transaction_id, violation_type, policy_citation, confidence_score}
Pillar 2: Memory
Memory distinguishes between short-term session state and long-term persistent knowledge.
Short-term memory (in-context): Current session data like user IDs, applied filters, partial results carried across reasoning steps. Limited by context window size and subject to context rot.
Long-term memory (external/persistent): Summaries and facts stored outside the context window in databases or vector stores, retrieved when needed. Enables cross-session continuity but adds tool-call overhead.
Anthropic's March 2026 cookbook documented structured memory tools where agents write to persistent storage. Testing showed memory management reduced peak context in follow-up sessions from 333,977 to 172,623 tokens — a 48% reduction.
Without deliberate memory management, filters and decisions bleed between steps or disappear across sessions entirely. That lost continuity is exactly what knowledge retrieval addresses.
Pillar 3: Knowledge Retrieval
Retrieval-Augmented Generation (RAG) pulls external, up-to-date facts into context from documents, databases, or knowledge graphs. Good retrieval returns small, precise, source-cited facts, not large raw document dumps, so the model reasons over evidence rather than guessing.
Research shows RAG reduces hallucination rates by 30–70% across domains, with grounded retrieval pushing hallucinations below 2% in structured domains. The market reflects this impact: RAG is projected to grow from USD 1.94 billion in 2025 to USD 9.86 billion by 2030 (38.4% CAGR).
Critical insight: Retrieval quality matters more than quantity. The Chroma study found that distractors — topically related but factually wrong content — cause worse model degradation than irrelevant content does. Enterprise RAG systems must prioritize precision over recall.
Pillar 4: Tools and Actions
Where retrieval pulls in knowledge, tools act on it. API calls, function calls, and database queries each inject clean, typed facts into context for the next reasoning step.
Tool design principles:
- Return compact, structured records (e.g.,
{ticket_id, status, assigned_to, sla_deadline}) rather than raw text - Validate inputs before execution so the model chains steps predictably
- Make tool names and descriptions unambiguous to avoid confusion
- Design tools to be self-contained with clear single responsibilities
Anthropic identified that tools must be token-efficient and unambiguous. A well-designed tool returning 200 tokens of structured data outperforms a poorly designed one that returns 2,000 tokens of unstructured text.
Practical Context Engineering Techniques for AI Agents
Each of the following techniques addresses a specific failure mode in enterprise AI agents — from retrieval gaps to context overflow to coordination overhead.
Hybrid RAG: Combining Semantic and Structured Retrieval
Hybrid RAG combines vector (semantic) search with keyword filters and structured graph traversals. This handles both fuzzy semantic queries ("tickets about authentication issues") and precise lookups (exact IDs, dates, product names).
Research by Akarsu et al. (April 2026) benchmarked 10 retrieval strategies on financial question answering:
| Retrieval Method | Recall@5 | Improvement vs. Dense |
|---|---|---|
| Hybrid + Cohere Rerank | 0.816 | +39.0% |
| Hybrid RRF (BM25 + Dense) | 0.695 | +18.4% |
| Dense (baseline) | 0.587 | — |
Neural reranking delivered the single largest improvement. The study also found BM25 outperformed dense retrieval on financial documents, countering assumptions that neural embeddings always dominate.
Implementation approach:
- Use sparse retrieval (BM25) for exact matches and keyword queries
- Use dense retrieval (embeddings) for semantic similarity
- Combine results using Reciprocal Rank Fusion
- Apply neural reranker as post-retrieval step
- Keep only top-k most relevant results within token budget
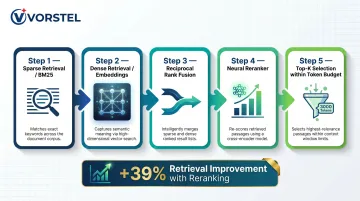
Organizations should not default to vector-only RAG — hybrid with reranking consistently outperforms single-method approaches.
Context Compaction and Summarization for Long Tasks
Context compaction addresses the challenge of long-running agents approaching context window limits. Anthropic's compaction API distills context into high-fidelity summaries.
Key findings from Anthropic testing:
- Peak context reduced from 335,279 to 169,164 tokens
- A ~170,000-token history distilled into ~2,783-token summary
- Preservation of architectural decisions, unresolved questions, and key facts
- Discard of redundant content and obscure specifics
When to use each approach:
- Compaction: Continuous workflows nearing token limits, where lossy compression is acceptable
- Tool-result clearing: Large tool outputs no longer needed, preserving conversation structure losslessly
- Note-taking: Iterative multi-session tasks requiring precise cross-session memory
Compaction triggers at configurable thresholds (minimum 50K tokens, default 150K). It's lossy by design but maintains high-level accuracy for ongoing reasoning.
Context Ordering and Formatting
Models attend more to content placed earlier in context. Stanford's "Lost in the Middle" research found performance degrades significantly when relevant information appears later in long contexts.
Recommended layout:
- Instructions and constraints (highest priority)
- Retrieved evidence and facts
- Examples demonstrating desired behavior
- Session history
- User request
Use clear headings or XML tags to delineate sections. Measure impact of layout changes using groundedness and accuracy metrics rather than guessing.
Example:
<instructions>
[System prompt and rules]
</instructions>
<evidence>
[Retrieved documents, database records]
</evidence>
<examples>
[Few-shot demonstrations]
</examples>
<history>
[Prior conversation turns]
</history>
<user_request>
[Current query]
</user_request>
Multi-Agent Context Isolation
Multi-agent patterns use specialized sub-agents with clean, focused context windows for parallel tasks, coordinated by an orchestrator. Each sub-agent returns compact summaries rather than raw outputs.
Google Research findings showed multi-agent coordination delivers +81% improvement on parallelizable tasks but causes up to 70% degradation on sequential ones. Task parallelizability is the decisive architectural factor.
Anthropic found systems using Claude Opus as lead agent with Sonnet sub-agents outperformed single-agent systems by 90.2% on breadth-first research tasks. Sub-agents typically return 1,000-2,000 token summaries after exploring larger datasets.

Trade-off: A UIUC study found multi-agent systems consume 4x to 220x more tokens than single-agent counterparts. Optimized configurations still require 2x to 12x more response tokens.
When to use multi-agent:
- Tasks with genuinely independent sub-problems
- Research workflows requiring breadth-first exploration
- Scenarios where context isolation prevents contamination
When to avoid:
- Sequential workflows with strong dependencies
- Cost-sensitive applications with tight token budgets
- Tasks where coordination overhead exceeds parallelism benefits
Enterprise Implementation Considerations
Deploying these techniques at enterprise scale requires coordinated decisions across several layers:
- Data pipelines — ingestion, chunking, and indexing strategies for retrieval systems
- Memory architecture — choosing between in-context, external, and hybrid memory stores
- Tool design — structuring outputs so agents receive compact, high-signal results
- Orchestration logic — defining when to route tasks to sub-agents vs. handle inline
Firms like Vorstel Technologies work with organizations to assess existing SAP, CRM, and data infrastructure and integrate context engineering pipelines into live enterprise environments.
Benefits and Common Pitfalls of Context Engineering
Benefits Worth Knowing
Fewer hallucinations and higher reliability: Grounding answers in retrieved facts reduces hallucination rates by 30-70%, with structured domains achieving less than 2%.
Coherent multi-step reasoning: Agents carry structured state across workflow steps, maintaining consistency throughout complex processes.
Explainability and auditability: Answers cite sources, paths, and IDs — no black-box outputs. This matters especially in regulated industries.
Lower token costs and latency: MVC discipline eliminates irrelevant content from context windows. Anthropic's compaction testing demonstrated ~50% token reduction without measurable accuracy loss on high-level facts.
Common Pitfalls to Avoid
Context rot: Accumulated errors in long sessions as attention degrades.
- Fix: Cap history length, summarize periodically, reset between tasks
Context confusion: Too many similar tools causing selection errors.
- Fix: Name tools clearly, add selection rules in instructions, limit tool count
Context distraction: Oversized windows bias model toward recent actions.
- Fix: Prune repeated content, cap retrieval to top-k results, use reranking
Context poisoning: Untrusted inputs contaminating reasoning.
- Fix: Restrict write paths, require citations for claims, audit information lineage
Forbes identified context management failures among the five failure modes holding back AI agents. Neo4j's Michael Hunger stated: "Most production issues stem from gaps in context, not limits in the model itself."

Measuring Context Engineering Effectiveness
Knowing what can go wrong is only half the picture — you also need a way to confirm things are going right. Track these metrics:
Groundedness: Does the answer cite evidence from retrieved context? Measure percentage of claims with source citations.
Task completion rate: For multi-step workflows, track successful end-to-end completion without human intervention.
Token efficiency: Measure tokens consumed per task phase. Compare before and after implementing MVC practices.
Retrieval quality: Test on real queries by measuring:
- False positives (irrelevant documents retrieved)
- False negatives (relevant documents missed)
- Position of first relevant result (MRR)
Before selecting evaluation tools, one finding from an Atlan benchmark study testing 1,460 questions across major frameworks is worth flagging: all tested tools failed to distinguish factually wrong contexts from correct ones when entities matched. Hard negatives — entity-swapped passages with correct entities but wrong answers — scored higher than partial contexts. Keep this blind spot in mind when choosing your stack.
Framework recommendations:
- TruLens: Best for agentic systems with OpenTelemetry-based tracing and RAG Triad metrics (Context Relevance, Groundedness, Answer Relevance)
- DeepEval: Preferred for CI/CD enforcement with 50+ metrics and native Pytest integration
- RAGAS: Fastest path for focused RAG quality evaluation (Faithfulness, Answer Relevancy, Context Precision/Recall)
Use multiple tools in combination, and include adversarial test cases — especially in domains like legal, financial, and medical where entity confusion carries high stakes.
Frequently Asked Questions
What is context engineering in AI?
Context engineering is the discipline of designing systems that select, structure, and deliver the right information and tools to an LLM at each step of a task — beyond just writing a prompt — so the model can reason accurately and reliably. It addresses the "what the model knows" problem that causes most enterprise AI failures.
What is an AI content engineer?
The correct term is AI context engineer — a developer or AI engineer who designs the information pipelines, retrieval systems, memory stores, and tool integrations that shape what a model sees at inference time. This is distinct from a content engineer, who creates written material.
What is an example of context engineering in AI?
A customer support agent that, before responding, automatically retrieves the customer's account history, open tickets, applicable SLA policy, and product documentation — rather than relying solely on the model's training knowledge — producing grounded, accurate responses.
What are the 4 pillars of context engineering?
The four pillars are:
- Instructions: System prompt defining the model's role and operating rules
- Memory: Short-term session state plus long-term persistent knowledge
- Knowledge Retrieval: RAG and structured retrieval of up-to-date facts
- Tools and Actions: Function calls that inject clean, structured data at runtime