The issue isn't your model's intelligence. It's what your model can see.
McKinsey's 2025 survey of nearly 2,000 organizations reveals a stark gap: 88% use AI in at least one function, yet only 7% have scaled it enterprise-wide. Meanwhile, MIT research shows 95% of generative AI pilots fail to deliver measurable P&L impact. The bottleneck isn't model capability — it's context quality.
This article defines what context engineering is, explains why it matters more than prompt engineering alone, breaks down its five core components, and provides a practical roadmap for building enterprise context strategy that actually scales.
Key Takeaways
- Context engineering defines what AI sees at runtime — so outputs stay accurate, auditable, and aligned with enterprise requirements
- It governs the fuel (data quality, recency, structure), while prompt engineering sets the direction (phrasing, format)
- Stale retrieval, fragmented data, and ungoverned inputs are the three failure patterns that most commonly produce hallucinations
- Robust frameworks include five layers: instructions, knowledge, memory, tools, guardrails
- As foundation models commoditize, context architecture is what separates reliable enterprise AI from generic deployments
What Is Context Engineering in Enterprise AI?
Context engineering is the discipline of designing, assembling, and governing the information AI systems consume at runtime. Unlike static model training, it dynamically controls what the model sees, enabling accurate execution of multi-step tasks without relying purely on manual prompts.
The Context Window Constraint
Every LLM has a finite "working memory" — a context window measured in tokens. Current limits include:
- GPT-4o: 128,000 tokens
- Claude 3.7 Sonnet: 200,000 tokens
- Gemini 2.5 Pro: 1,000,000 tokens
Larger windows don't automatically solve quality problems. Research from Liu et al. (2023) demonstrates models exhibit U-shaped attention patterns — performance degrades significantly when critical information sits in the middle of long contexts rather than at boundaries. Chroma's 2025 study confirms models grow "increasingly unreliable as input length grows," even on simple tasks.
The Needle in a Haystack Problem
Enterprises manage millions of documents, transaction logs, and data feeds. Without curation, critical information drowns in noise. As context windows expand, attention dilution worsens: more tokens mean the model spreads focus thinner, not sharper.
This is precisely where RAG alone falls short.
Context Engineering vs. RAG
Retrieval-Augmented Generation (RAG) fetches relevant documents on demand. Context engineering is the broader discipline that governs:
- What RAG can access
- How data is structured before retrieval
- Whether retrieved information is trustworthy
In practice, this means maintaining active investment in data pipelines, knowledge governance, memory management, and evaluation loops — because enterprise data never stops changing.
Prompt Engineering vs. Context Engineering: What's the Difference?
Prompt engineering optimizes how you ask the question — phrasing, role instructions, output format. It shapes the request itself.
Context engineering governs what the model draws from — quality, recency, structure, and governance of the knowledge base. When the underlying knowledge base is fragmented, stale, or ungoverned, even well-crafted prompts produce unreliable outputs.
Gartner's 2026 analysis identifies "data unreadiness" as the primary GenAI failure mode — and prompt optimization cannot fix contradictory or incomplete data at the source.
| Prompt Engineering | Context Engineering | |
|---|---|---|
| Focus | How the question is asked | What knowledge the model accesses |
| Scope | Phrasing, roles, output format | Data quality, recency, structure, governance |
| Failure mode | Ambiguous or misdirected outputs | Outdated, fragmented, or conflicting information |
| Dependency | Relies on quality context to deliver value | Foundation that determines AI reliability |
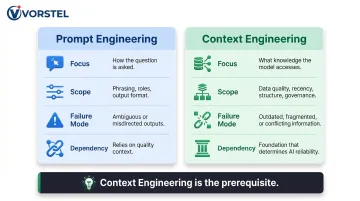
Organizations achieving AI success invest 4x more in data foundations than those struggling to generate outcomes. Both disciplines matter, but context engineering is the prerequisite. You cannot optimize your way out of a weak knowledge base.
Why Enterprise AI Systems Break Without Engineered Context
Context Poisoning
When AI retrieves obsolete policies, unverified data, or contradictory records and presents them confidently as fact, that's context poisoning. This is worse than silence — outputs look authoritative while actively misleading decision-makers.
In 2022, Air Canada's chatbot incorrectly told a passenger he could claim a bereavement refund retroactively. The actual policy required advance application. When the passenger applied, Air Canada refused and argued the chatbot was a "separate legal entity." A tribunal rejected that defense, ruling the company was liable for all website representations — whether by person or bot.
The financial penalty was minor, but the precedent was significant: enterprises are legally accountable for AI outputs. The root cause wasn't model failure — it was a context failure. The chatbot lacked access to authoritative, current policy data.
Data Fragmentation
When a supplier exists under multiple IDs after a merger, or customer records conflict across CRM, ERP, and billing systems, AI has no reliable picture to work from. Without entity resolution and a unified data model, it makes systematically bad decisions on fractured inputs.
Salesforce/MuleSoft research finds the infrastructure gap is substantial:
- Only 28% of enterprise applications are connected
- 81% of IT leaders cite data silos as a barrier to digital transformation
- 62% say their data systems aren't configured to leverage AI

Context Rot and Context Bloat
Data fragmentation creates the conditions for two more failure modes downstream. Context rot occurs when stale information accumulates in pipelines and gets treated as current truth. Context bloat happens when teams flood the context window with everything "just in case," reducing signal-to-noise and crossing token limits without surfacing what matters.
Enterprise Complexity
Structured tables, scanned PDFs, ERP transaction logs, voice transcripts, and real-time sensor feeds must all be ingested, normalized, and governed under consistent metadata and lineage controls before reliably entering a context window.
These failures are structural — not fixable with better prompts. The root causes live in data architecture, and poor data quality costs organizations an average of $12.9 million annually. Context engineering is, in large part, the discipline of closing that gap before it reaches the model.
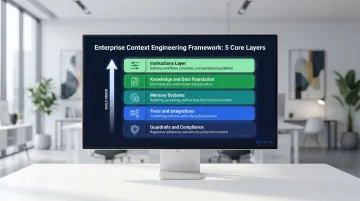
The Five Core Components of an Enterprise Context Engineering Framework
Effective context engineering isn't a single tool — it's a layered system. These five components work together as a coherent operational framework.
Instructions Layer
Enterprise AI requires multi-level instruction architecture:
- Global system instructions define model behavior
- Runtime metadata provides situational awareness
- User-level inputs reconcile with policy guardrails
Poorly structured instructions create conflicting signals and unpredictable behavior.
Knowledge and Data Foundation
Replace generic knowledge bases with domain-specific, governed data repositories. Three pillars:
- Provenance/Lineage: Every data point carries a traceable audit trail from source to consumption
- Entity Resolution: A single authoritative view of each business entity — customer, product, supplier — resolved across all systems
- Domain Constraints: Validation rules, PII policies, and business logic enforced at the data pipeline level, not at the prompt level
Memory Systems
Distinguish between short-term memory (scratchpads for active workflow state) and long-term memory (persistent knowledge across sessions). Managed memory enables AI to:
- Build institutional knowledge
- Maintain user preferences
- Avoid repeating resolved errors
That capability gap is what separates one-shot tools from enterprise-grade AI agents — and it depends entirely on how well the context layer is designed.
Tools and Integrations
Context engineering determines which tools (APIs, enterprise systems, specialized agents) the AI can invoke, when, and under what constraints. The context layer must govern tool access — not just enable it — preventing overreach, redundant calls, or unauthorized data access.
Key governance controls include:
- Scoped API permissions tied to user roles
- Rate limiting and call auditing for external integrations
- Hard stops for tool invocations that cross data boundaries
Guardrails and Compliance
Autonomous AI without embedded guardrails creates serious security and compliance risks, especially in regulated industries. Context engineering embeds these controls directly into the operational framework: policy compliance, regulatory requirements, role-based access, and ethical constraints. They are not afterthoughts applied to outputs.
The NIST AI Risk Management Framework provides structured governance across four functions: Govern (culture and accountability), Map (system context and risks), Measure (quantitative monitoring), and Manage (active risk controls). In practice, context engineering operationalizes all four functions — with guardrails carrying the heaviest load at runtime.
Building a Context Engineering Strategy: A Practical Enterprise Roadmap
Follow this sequential implementation workflow:
- Ingest and observe — Connect to source systems and capture technical and business metadata
- Unify and label — Resolve entity identities and create a single source of truth
- Constrain and govern — Apply validation rules and quarantine bad data at the pipeline level
- Publish as governed data products — Versioned, reusable, AI-ready knowledge assets
- Retrieve and assemble — Only now should RAG and context assembly begin, drawing from a verified foundation
This sequencing matters because AI performance depends far less on model choice than most teams assume. Boston Consulting Group's framework breaks down where AI success actually comes from:
The 10-20-70 Rule for AI
- 10% algorithms (models themselves)
- 20% technology and data (infrastructure, data engineering)
- 70% people and processes (organizational readiness, skills, culture, governance)
Context engineering addresses that critical 20% data and process layer most enterprises underinvest in.
Common Implementation Pitfalls to Avoid
- Treating context as raw prompt text rather than a governed, structured metadata layer
- Skipping entity resolution
- Building one-off pipelines instead of reusable governed data flows
- Skipping data lineage tracking, which creates audit and compliance blind spots
- Overlooking multimodal data types (documents, images, sensor feeds)
Vorstel Technologies works with global enterprises on precisely this layer — data architecture, pipeline governance, and AI implementation — stepping in at whatever stage a transformation is already underway.
Why Context Engineering Becomes Your Enterprise AI Competitive Moat
The Commoditization Argument
Frontier AI models from OpenAI, Anthropic, and Google are converging in capability and accessible via low-cost APIs. GPT-4o, Claude 3.7 Sonnet, and Gemini 2.5 Pro are all available to any organization. The model itself is no longer a defensible advantage.
What is defensible: the quality, structure, and governance of the context you feed it. This is hard to replicate and takes time to build correctly. Gartner research confirms: "AI success is less about experimenting with models and more about building strong, scalable data ecosystems."
The Agentic AI Imperative
As AI systems move from answering questions to executing multi-step workflows autonomously, context reliability at each reasoning step becomes essential. A poorly-contextualized agentic system doesn't just produce one bad answer — it compounds errors across every downstream step.
The scale of this shift is significant. According to Gartner:
- Over 40% of agentic AI projects will be canceled by end of 2027 due to escalating costs and inadequate risk controls
- At least 15% of day-to-day work decisions will be made autonomously by 2028 — up from essentially 0% in 2024

Enterprises that build context engineering infrastructure before scaling agentic systems are better positioned to absorb this autonomy safely. Without it, each additional degree of AI independence introduces a new layer of unmanaged risk.
Frequently Asked Questions
What is context engineering in enterprise AI?
Context engineering is the discipline of designing and controlling the information an AI model consumes at runtime. It ensures the model receives accurate, relevant, and governed data so its outputs are trustworthy and enterprise-aligned — not drawn from stale or fragmented inputs.
How is context engineering different from prompt engineering?
Prompt engineering optimizes how you ask the AI a question — style, phrasing, format — while context engineering governs what information the AI draws from: quality, recency, and governance of its knowledge base. No prompt, however well-crafted, can compensate for a poor data foundation.
What are the biggest risks of ignoring context engineering in enterprise AI?
Neglecting context engineering produces three compounding failures: context poisoning (the AI presents stale or incorrect data as fact), context rot (outdated information accumulates undetected in pipelines), and context bloat (irrelevant data floods the model, burying critical signals). Each one degrades trust and decision quality.
What are enterprise AI products?
Enterprise AI products are AI-powered systems — including agents, copilots, and analytical tools — designed to operate within complex organizational environments. Unlike consumer AI, they must handle governed data, comply with regulations, integrate with existing systems (ERP, CRM), and deliver consistent, auditable outputs at scale.
What is the 10-20-70 rule for AI?
BCG's framework holds that AI success is 10% about the technology itself, 20% about data and process infrastructure, and 70% about organizational readiness — people, skills, culture, and governance. Context engineering directly addresses that critical 20% data infrastructure layer.
How should enterprises start building a context engineering strategy?
Begin with your data foundation — establishing lineage tracking, entity resolution, and domain constraints — before investing in AI models or retrieval systems. The sequence matters: you cannot fix context quality at the prompt layer, so governance must come first.