Introduction
Enterprises investing in AI tools often face a frustrating reality: demos that dazzle during proof-of-concept become unreliable in production. Despite heavy investment in advanced models and carefully crafted prompts, organizations encounter inconsistent outputs, hallucinations, and results that fail to deliver business value at scale.
For years, prompt engineering has been the dominant strategy for improving AI performance. But as AI agents take on complex, multi-step workflows across enterprise systems, prompt engineering alone falls short. The problem isn't the model—it's the information environment the model operates in.
Context engineering directly improves AI model performance through measurable outcomes: higher accuracy, faster scalability, and lower operational costs. Organizations that treat context as infrastructure, not an afterthought, will consistently outperform those that don't.
Key Takeaways
- Context engineering shapes the full information environment fed to AI models—memory, retrieved data, tools, and instructions—not just the prompt
- Production AI fails primarily because context is incomplete, noisy, or poorly structured—not because models lack capability
- Core advantages include sharper output accuracy, scalable deployment, and measurably lower token costs
- Without it, deployments hit rising costs, unreliable outputs, and a hard ceiling on scale
- Treating context as infrastructure separates production-ready AI from systems that only work in demos
What Is Context Engineering (Brief Context)
Context engineering is the systematic practice of assembling and optimizing the complete set of inputs an AI model uses at inference time (when the model generates a response). This includes system instructions, retrieved knowledge through RAG (retrieval-augmented generation), user history, tool definitions, memory layers, and guardrails. The goal is to consistently achieve desired outputs in production environments.
This discipline applies primarily in:
- Agentic AI deployments handling multi-step workflows
- Domain-specific enterprise use cases like customer support, document processing, and code generation
- SAP, ERP, and CRM workflow automation
- Any scenario where prompt engineering alone produces unreliable results
Context engineering isn't about adding more data—it's about supplying the right data, in the right structure, at the right time.
Anthropic defines it as "the set of strategies for curating and maintaining the optimal set of tokens during LLM inference," emphasizing the principle of finding the "smallest possible set of high-signal tokens."
Key Advantages of Context Engineering
The advantages below tie directly to measurable, operational outcomes—accuracy rates, deployment timelines, cost per query, and reliability at scale. These benefits compound over time: organizations that invest in context engineering early gain structural advantages as they scale AI deployments.
Advantage 1: Higher AI Output Accuracy and Reduced Hallucinations
Context engineering addresses the fundamental reason most production AI fails: models receive incomplete, irrelevant, or contradictory information rather than being inherently incapable. When AI systems hallucinate or produce incorrect outputs, the issue typically lies in what the model sees, not what it can do.
By curating only high-signal, relevant tokens—through retrieval-augmented generation, precisely crafted system prompts, and dynamic memory management—context engineering ensures models have exactly what they need to generate accurate, grounded responses. Instead of filling information gaps with fabricated content, properly engineered context grounds outputs in verified, retrieved information.
The Business Cost of Hallucinations
AI hallucinations cost businesses $67.4 billion in losses in 2024. These errors create downstream consequences: rework, compliance exposure, and eroded user trust. 47% of executives admitted making major business decisions based on faulty AI-generated content.
The impact extends beyond financial costs. In the legal sector, three attorneys were fined between $1,000 and $3,000 for submitting court filings containing eight AI-generated fake case citations. Air Canada was held liable for $812 in damages after its chatbot provided incorrect bereavement fare information.
Research validates context engineering's effectiveness: RAG systems reduce hallucination rates by 30% to 70% across domains, and grounded retrieval lowers hallucinations to less than 2% in summarisation tasks.

Accurate, context-grounded outputs enable leaders to trust AI for high-stakes workflows—finance, legal, customer support—rather than restricting it to low-risk use cases.
KPIs Impacted:
- Output accuracy rate
- Hallucination frequency
- Query resolution rate
- Escalation rate in support workflows
- Compliance error rate
When This Advantage Matters Most:
Accuracy gains prove highest in:
- Domain-specific deployments where models lack specialized training data (healthcare, legal, proprietary enterprise systems)
- Long-horizon, multi-turn agent interactions
- Any workflow where incorrect outputs carry financial or reputational consequences
Advantage 2: Scalability — Moving from Pilot to Production-Grade AI
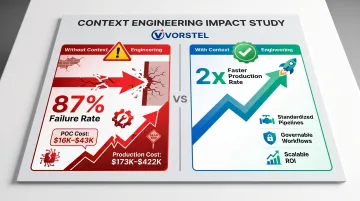
Most AI pilots succeed in controlled settings but collapse when scaled. Gartner found that at least 50% of generative AI projects were abandoned after proof of concept, citing poor data quality, inadequate risk controls, escalating costs, or unclear business value.
The numbers are stark: 87% of AI projects fail at production because POCs test algorithms in isolation while production requires operational infrastructure costing 10x to 20x more. POC costs typically run $16,000–$43,000; first-year production deployment costs $173,000–$422,000.
Context engineering transforms AI from ad hoc prompting to repeatable, testable workflows. By standardizing context pipelines—reusable templates, consistent retrieval strategies, and structured input formats—organizations shift to governable AI that performs consistently across thousands of interactions.
Organizations that master GenAI implementation fundamentals move from pilot to production at twice the rate of those that don't. Treating context as infrastructure, rather than improvising per deployment, is what separates the two groups.
The Scaling Gap in Practice
Scaling AI without context engineering forces reactive firefighting—constant prompt tweaking, edge case management, and individual tuning. Well-engineered context pipelines behave predictably as volume grows, reducing time-to-deploy for new use cases because teams build on established infrastructure rather than starting from scratch.
McKinsey research shows that while 72% of organizations report using generative AI (up from 33% in 2024), nearly two-thirds have not yet begun scaling AI across the enterprise. Only 39% report any EBIT impact from AI; approximately 6% attribute more than 5% of EBIT to AI.
KPIs Impacted:
- Time-to-production for new AI use cases
- Deployment consistency rate
- Volume handled per AI instance
- Manual intervention rate
- Engineering hours spent on AI maintenance
When This Advantage Matters Most:
Scalability benefits prove most pronounced for:
- Enterprises deploying AI across multiple departments or geographies simultaneously
- Organizations running multi-agent workflows where multiple systems must share context coherently
- Fast-growing companies that cannot afford manual prompt management at scale
Advantage 3: Reduced Operational Cost Through Token Efficiency
Every token processed by an LLM carries a cost in compute, latency, and money. Poorly engineered context—stuffed with irrelevant data, redundant history, or unstructured noise—drives up costs while simultaneously degrading performance through "context rot."
Context engineering deliberately curates the smallest set of high-signal tokens by compressing conversation history, filtering redundant tool outputs, and prioritizing recent and relevant data. This reduces per-query costs, improves response speed, and prevents the model's attention from being diluted.
Understanding Context Rot
Anthropic's research describes context rot as the phenomenon where "as the number of tokens in the context window increases, the model's ability to accurately recall information from that context decreases."
LLMs have a "finite attention budget" due to transformer architecture, creating n-squared pairwise relationships for n tokens. As context length grows, this produces "reduced precision for information retrieval and long-range reasoning."
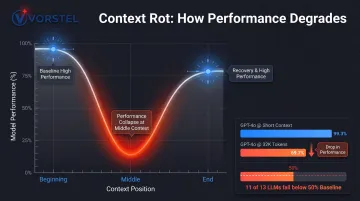
Stanford/UC Berkeley research demonstrated that LLM performance exhibits a U-shaped curve: models perform significantly better with information at the very beginning or end of context, with sharp performance degradation for information in the middle—even for models specifically trained for long contexts.
The NoLiMa benchmark accepted at ICML 2025 found that 11 out of 13 LLMs evaluated dropped below 50% of their strong short-length baselines when context reached 32,000 tokens. GPT-4o fell from a 99.3% short-length baseline to 69.7% at longer contexts.
Cost Implications at Scale
A single enterprise query often consumes 50,000 to 100,000 tokens before reasoning even begins. Gartner identifies escalating TCO from token usage, model hosting, and inference charges as "budget black holes"—negligible per-token costs during POC transform into a Total Cost of Ownership problem when scaled across thousands of users.
Leaner, well-structured context not only lowers cost per query but also enforces guardrails more reliably. Compliance rules and safety constraints embedded in tighter context are less likely to be lost as model attention dilutes.
KPIs Impacted:
- Cost per query/API call
- Latency (response time)
- Context window utilization rate
- Token waste rate
- Guardrail compliance rate
When This Advantage Matters Most:
Token efficiency gains prove most impactful for:
- Organizations running high-volume AI workflows (thousands of queries daily)
- Long-horizon agentic tasks where context windows balloon without active management
- Enterprises with strict cost controls or real-time latency requirements
What Happens When Context Engineering Is Missing or Ignored
When organizations deploy AI without context engineering discipline, a predictable failure pattern emerges. Systems that perform well in demos produce erratic, unreliable results in production — forcing teams into constant manual intervention rather than scaling.
McKinsey found that 51% of organizations have experienced at least one negative consequence from AI deployment, with inaccuracy being the most common risk, experienced by 30% of organizations.
The compounding consequences include:
- Hallucinations and factual errors that erode user trust and create compliance exposure across legal, financial, and regulatory workflows
- Inconsistent outputs across similar queries, making AI unreliable for business decisions and requiring human review of every result
- Escalating costs as unmanaged token usage grows and engineering time shifts from strategic work to prompt firefighting
- Inability to scale beyond isolated pilots, trapping AI in experimental status rather than becoming enterprise infrastructure
- Context drift in long-running agents, where the model loses track of earlier reasoning, makes contradictory decisions, and requires costly restarts
These aren't edge-case failures — they reflect a structural gap in how most organizations approach AI deployment. Gartner predicts that through 2026, organizations will abandon 60% of AI projects unsupported by AI-ready data, with 63% of organizations either lacking or uncertain they have the right data management practices for AI. Context engineering directly addresses this gap.
How to Get the Most Value from Context Engineering
Context engineering works best when treated as infrastructure, not a one-off project. Apply the same rigor to context assembly, maintenance, and auditing that you would to API management or data governance.
Key operational practices that drive results:
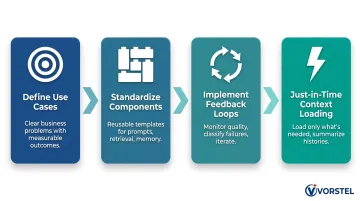
- Start with well-defined use cases — build context pipelines on top of clear business problems with measurable outcomes and identified data sources. Clarity on objectives enables better context design from the start.
- Standardize context components — create reusable templates for system prompts, retrieval strategies, and memory management so teams can scale new AI use cases without rebuilding from scratch. AI high performers are 2.8x more likely to engage in fundamental workflow redesign (55% versus 20% of others).
- Implement feedback loops — monitor output quality continuously, classify failures as context failures versus model failures, and iterate on retrieval ranking, prompt structure, or memory management. High performers are far more likely to have defined human-in-the-loop validation processes (65% versus 23%).
- Apply just-in-time context loading — load only what the model needs at each step, use conversation summarization to compact long histories, and have sub-agents return condensed outputs rather than full context chains.
For enterprises earlier in their AI journey, partnering with a specialist can shorten the path from experimental prompting to production-grade pipelines. Vorstel Technologies helps global organizations build and operationalize AI systems across SAP, cloud, and custom software environments—taking over at whatever stage a project currently sits.
Conclusion
Context engineering is the operational discipline that closes the gap between AI's potential and its real-world performance. It provides the control, clarity, and consistency that prompt engineering alone cannot deliver.
Organizations that build context engineering as infrastructure today will deploy new AI use cases faster and at lower cost as capabilities continue to advance. That advantage is already visible: while 87% of AI projects fail at production, those with standardized context pipelines reach production at twice the rate of those without.
Context engineering requires the same ongoing discipline as data governance or software architecture — not a one-time configuration, but a practice that matures alongside the systems it supports. The teams that invest in it now will find themselves with a structural advantage when the next wave of AI capabilities arrives.
Frequently Asked Questions
What is effective context engineering for AI?
Effective context engineering means deliberately curating the smallest, highest-signal set of tokens (system instructions, retrieved knowledge, memory, and tools) that maximizes the likelihood of the model producing correct, reliable outputs consistently across production deployments.
Why is context engineering important when building AI agents?
AI agents operate over multiple turns and long time horizons, generating growing volumes of data that must be managed. Without engineered context, agents lose coherence, repeat mistakes, or fill gaps with hallucinated information, making reliable autonomous operation impossible.
How is context engineering different from prompt engineering?
Prompt engineering focuses on phrasing a single instruction to get a good output, while context engineering governs the entire information environment the model operates in—including memory, retrieved data, tools, and guardrails—making it the broader, more foundational discipline.
What is "context rot" and how does it impact AI model performance?
Context rot refers to degradation in model accuracy and recall as the context window fills with excessive or irrelevant tokens. As context grows, the model's attention becomes diluted, reducing its ability to reason accurately or retrieve key information from earlier in the context.
What are the key components of a well-engineered context?
A well-engineered context combines six elements:
- System instructions (role definition and rules)
- The user query
- Retrieved knowledge via RAG
- Memory — both short-term and long-term
- Tool definitions
- Guardrails and compliance constraints
How can enterprises begin implementing context engineering?
Start by identifying high-value AI use cases with clear data sources and measurable outcomes. Then build standardized context pipelines for those use cases — treating context as infrastructure — and iterate based on output quality monitoring and failure analysis.