Introduction
Most failures in production AI agents aren't model failures. They are context failures. According to Anthropic's engineering team, bloated, poorly structured, or irrelevant information reaching the model is the silent killer of agent reliability. As Cognition observed in mid-2025, context engineering has become "effectively the #1 job of engineers building AI agents."
The challenge is real: tool results alone can consume over 50,000 tokens before an agent even processes a user request. Multi-agent systems use up to 15x more tokens than simple chat. With Claude Opus 4.7 input tokens priced at $5 per million and context windows now reaching 1 million tokens, unchecked context accumulation creates both performance degradation and significant cost exposure at scale.
This guide explains what context engineering is, how it differs from prompt engineering, what fills the context window, how to implement it systematically, and how to avoid the failure modes that plague real-world deployments.
Key Takeaways
- Context engineering decides what enters an AI agent's context window at every reasoning step—what to include, compress, retrieve, and discard
- Context windows are finite and costly: unchecked accumulation degrades attention quality and drives up token costs fast
- Four core strategies keep context lean: offload static content, retrieve dynamically, isolate per task, and compress history
- Context rot, pollution, and confusion are architectural problems—not model limitations—and are fully preventable
- For complex tasks, combine context compaction, structured note-taking, and multi-agent architectures to maintain coherence at scale
What Is Context Engineering (and Why It Goes Beyond Prompt Engineering)
Context engineering is the discipline of designing, selecting, and organizing all information an LLM receives before generating a response. That includes:
- System prompts and user instructions
- Conversation history and memory
- Retrieved documents and tool outputs
- Any data injected at inference time
As Anthropic defines it: "the set of strategies for curating and maintaining the optimal set of tokens during LLM inference, including all the information that may land there outside of the prompts."
From Prompt Engineering to Context Engineering
Prompt engineering optimized individual instructions for one-shot tasks. Context engineering emerged as agents became multi-step, multi-turn systems requiring dynamic management of evolving information. As Andrej Karpathy put it on X: "People associate prompts with short task descriptions you'd give an LLM in your day-to-day use. When in every industrial-strength LLM app, context engineering is the delicate art and science of filling the context window."
The key distinction: prompt engineering produces a fixed instruction written once. Context engineering is iterative—the curation decision repeats at every inference step as conversation, tool outputs, and retrieved data evolve. That iterative nature makes one constraint impossible to ignore: computational cost scales with every token you add.
The Attention Budget Constraint
LLMs allocate attention across all tokens — much like humans with limited working memory. The architectural reason is fundamental: transformer self-attention scales at O(n² × d) where n = sequence length and d = representation dimensionality. This quadratic cost means computational expense grows rapidly as context fills.
Performance degrades before hitting token limits. Chroma's study of 18 LLMs confirmed that "performance grows increasingly unreliable as input length grows," even on simple tasks. This phenomenon — called context rot — is non-uniform and task-dependent, with no single fixed threshold. Degradation accelerates when retrieval queries diverge from the specific facts buried in long context (needle questions).
The practical goal, then, is the smallest possible set of high-signal tokens that maximizes the probability of the desired outcome. Fewer, better-chosen tokens reduce costs and keep agents reliable at scale.
The Anatomy of Context: What Actually Fills the Window
Most developers underestimate how many competing inputs occupy the context window in production. Before engineering context, audit these four primary layers:
System Instructions
The agent's role, behavioral rules, tool descriptions, output format requirements, and few-shot examples. Largely static, this layer is the prime candidate for prefix caching. Caching it aggressively cuts costs substantially:
| Provider | Cached Input Price | Base Input Price | Savings |
|---|---|---|---|
| Anthropic | 0.1x base rate | — | ~90% reduction |
| OpenAI (GPT-4.1) | $0.25/1M tokens | $2.50/1M tokens | 90% reduction |

Conversation History
The running record of user turns, agent responses, tool calls, and results. This is the fastest-growing layer and the most commonly under-managed. Simple append-and-resend accumulates bloat quickly, consuming thousands of tokens on stale exchanges that no longer influence reasoning.
Retrieved Knowledge
Documents, database records, or memory items fetched from external stores. Without reranking or deduplication, retrieval pipelines return relevant-but-redundant content — and every redundant chunk displaces something more useful. Unfiltered RAG injects noise alongside signal.
Working State
Intermediate results, scratchpad reasoning, and task progress. Necessary for multi-step coherence but expensive if stored as verbose traces rather than structured summaries.
The Mental Model: RAM vs. Disk
Treat the context window as RAM (fast, finite, cleared between sessions) and external memory, databases, and file systems as disk (cheap, large, but requiring explicit retrieval). As LangChain frames it: "The LLM is like the CPU and its context window is like the RAM, serving as the model's working memory."
Good context engineering decides at each step what belongs in RAM now and what stays on disk until needed. The two core failure modes — loading irrelevant content and omitting what actually matters — both degrade output quality and drive up token costs. The following sections address how to avoid each.
How to Implement Effective Context Engineering: A Step-by-Step Approach
Step 1: Define the Agent's Purpose and Design the System Prompt
The system prompt is the most stable and impactful layer. Effective system prompts balance specificity and flexibility:
What makes a system prompt effective:
- Clear role definition stated in direct language
- Explicit output style and format requirements
- Safety rules and behavioral priorities
- Sufficient guidance without brittle hardcoding
Avoid two extremes:
- Brittle, hardcoded if-else instructions (fragile to maintain)
- Vague high-level guidance that falsely assumes shared context
The target: specific enough to shape consistent behavior, flexible enough that the model can reason through edge cases without breaking. OpenAI recommends organizing prompts using Markdown headers (H1-H4) or XML tags. Suggested structure:
## Role
[1-2 sentences defining the agent's function]
## Personality
[Communication style and tone]
## Goal
[Primary objective]
## Constraints
[What the agent should NOT do]
## Output Format
[Structure of responses]
Step 2: Separate Static from Dynamic Context
Implement a two-pass assembly pipeline:
- Static context (system prompt, cached instructions, long-lived summaries) loads first and enables prefix caching
- Dynamic context (current task state, fresh retrieval results, recent history) is injected second and kept minimal
This separation simplifies debugging—unexpected behavior traces to either static configuration (a prompt engineering problem) or dynamic state (a retrieval or history management problem).
Step 3: Manage Conversation History Deliberately
Naive history accumulation fails in long-running agents through two mechanisms:
- Context bloat: Stale tool outputs consuming tokens with no value
- Context poisoning: Earlier errors preserved and compounded in later reasoning
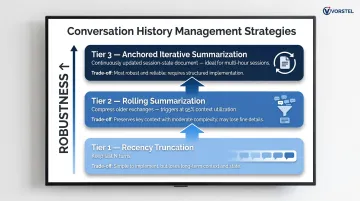
Three strategies in order of robustness:
Recency truncation: Keep the last N turns. Simple to implement, but long-term state disappears once exchanges scroll out of the window.
Rolling summarization: Compress older exchanges into structured summaries. Claude Code, for example, triggers auto-compact at 95% context utilization to handle this automatically.
Anchored iterative summarization: Continuously update a session-state document capturing intent, decisions, actions, and next steps. This is the most robust option for multi-hour sessions where earlier context directly affects later decisions.
Step 4: Design Retrieval as a Budget Decision
RAG is not simply "retrieve chunks, inject, proceed." Token cost stacks quickly in multi-retrieval workflows. Implement post-retrieval filtering—score and select only relevant results before injection.
Two factors that determine retrieval quality:
- Chunking strategy: Semantic chunking (splitting documents along natural topic boundaries) outperforms fixed-size chunking because it preserves meaning. Patsnap research found chunking strategy contributes 35% to final answer accuracy, ahead of re-ranking (28%) and context augmentation (22%).
- Retrieval control: Agent-controlled retrieval — where the model invokes retrieval as a tool when it recognizes need — produces targeted queries at the right moment. LangChain reports that applying RAG to tool descriptions improves tool selection accuracy by 3-fold.
Step 5: Keep the Tool Set Minimal and Well-Defined
Every tool schema occupies context. A bloated tool set leads to context confusion—the model hallucinates parameters or selects the wrong tool entirely. Tool selection is, at its root, a context budget problem.
Anthropic recommends: "Keep your three to five most-used tools always loaded" and use dynamic discovery for 10+ tools. Implement a hierarchical action space: a small set of core atomic tools with complex operations handled via general-purpose execution tools (e.g., bash/shell) rather than proliferating specific tools.
A practical test: if a human engineer cannot definitively say which tool to use in a given situation, the agent cannot be expected to either. Keeping tool definitions tight and purposeful is one of the highest-leverage decisions in agent architecture.
Advanced Techniques for Long-Horizon AI Agent Tasks
Context Compaction
When a conversation approaches the context window limit, the agent summarizes contents and reinitializes with a compressed version. The two approaches differ in an important way:
Compaction strips redundant information that exists elsewhere (reversible); summarization uses an LLM to compress history and is inherently lossy. Prioritize raw history first, compaction second, summarization only as a last resort.
What to keep:
- Architectural decisions and design constraints
- Unresolved issues and blockers
- Failed approaches (to prevent repetition)
- Current task dependencies
What to discard:
- Raw tool outputs already processed into decisions
- Redundant messages restating prior conclusions
Over-aggressive compaction loses subtle but critical context whose importance only emerges later. OpenAI recommends compacting "after major milestones" and treating compacted items as opaque state.
Structured Note-Taking (Agentic Memory)
The agent regularly writes notes to external memory (for example, a NOTES.md file or memory tool) and pulls them back into context as needed. This provides persistent state with minimal overhead.
Discipline required: Durable memory should only contain information that continues to constrain future reasoning — persistent preferences, decisions, failed approaches. Storing too much creates persistent context pollution. As Anthropic's engineering team notes: "Lossiness is a spectrum, not a binary."
Sub-Agent Architectures for Parallel Complexity
When single-agent memory management hits its limits, distributing work across specialized sub-agents is the next step. Rather than one agent maintaining state across an entire project, sub-agents handle focused tasks with clean, isolated context windows. The main agent coordinates via a high-level plan; sub-agents perform deep work and return condensed summaries targeting 1,000–2,000 tokens rather than full traces.
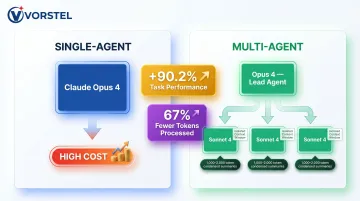
Implement the Agent-as-Tool pattern: treat complex sub-tasks as tool calls with defined input schemas and structured output. The performance case for this architecture is compelling:
- Multi-agent setup (Claude Opus 4 lead + Sonnet 4 sub-agents) outperformed single-agent Opus 4 by 90.2% on internal research evaluations, per LangChain's multi-agent architecture analysis
- The sub-agent pattern processes 67% fewer tokens overall compared to skills-based patterns
Common Failure Modes in Context Engineering (and How to Avoid Them)
Context Rot and Context Pollution
Context rot is performance degradation as the window fills (even within technical token limits) because the model's attention spreads too thin. Context pollution is the presence of irrelevant, redundant, or conflicting information that distorts reasoning.
Mitigation strategies:
- Define a pre-rot threshold (e.g., 60-70% of context capacity) and trigger summarization before hitting it
- Filter tool outputs strictly before injection
- Remove intermediate results no longer needed for current reasoning
Context Confusion and the Needle-in-a-Haystack Problem
Context confusion occurs when the model cannot distinguish between instructions, data, and structural markers. Research by Liu et al. measured GPT-3.5-Turbo-16k accuracy dropping from 88.2% (information at beginning) to 73.0% (information in middle position 10 of 20). Performance was highest when relevant information occurred at the beginning or end, a pattern known as the primacy and recency effects.
Mitigate with:
- Clear structural delimiters in prompts (XML tags or Markdown headers)
- Placing high-priority information at the beginning or end of context
- Reranking strategies ensuring most relevant retrieved content appears first
OpenAI recommends: "If you have long context in your prompt, ideally place your instructions at both the beginning and end of the provided context."
Neglecting Production Evaluation
Structural context failures like rot and confusion are easier to catch in isolation. What's harder to spot is how they compound over time in live systems. Context engineering failures are often invisible in test sessions but surface in longer real-world interactions. Implement probe-based evaluation: after compression or retrieval steps, ask targeted questions to verify critical information was preserved.
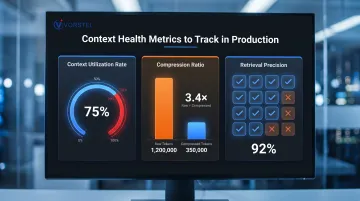
Track three context-specific production metrics:
- Context utilization rate: percentage of token budget consumed per inference step
- Compression ratio: token reduction achieved through summarization (raw ÷ compressed)
- Retrieval precision: whether injected chunks are actually influencing output, not being ignored
Also monitor for context drift. Early signals include:
- The agent re-reading files it already processed
- Restating decisions already made earlier in the session
- Gradually reframing the original task objective
Langfuse tracks token usage and cost by type (cached, prompt, completion, reasoning), but no MLOps platform has published standardized context metrics yet. Teams must define and instrument these themselves.
Frequently Asked Questions
What is the difference between context engineering and prompt engineering?
Prompt engineering focuses on crafting effective instructions for one-shot tasks. Context engineering manages the entire dynamic information state (memory, history, tools, retrieved data) across multi-step agent interactions. Every inference step becomes a curation decision, not just a writing exercise.
What is "context rot" and why does it degrade AI agent performance?
Context rot is performance degradation that occurs as the context window fills, even within advertised token limits. Transformer attention spreads thin across more tokens, slowing down significantly as sequences grow longer and reducing the model's ability to recall and reason over earlier content.
How much context should I provide to an AI agent?
The goal is the smallest possible set of high-signal tokens relevant to the current reasoning step—not maximum information. Overfilling the context with irrelevant or stale content increases cost, slows responses, and reduces accuracy through attention dilution.
What is context compaction and when should I use it?
Compaction is summarizing and restarting the context window when it nears its limit, preserving critical decisions and state while discarding redundant raw outputs. Trigger it proactively at a defined threshold (such as 60–70% utilization) before performance degrades, not after errors appear.
Is RAG always necessary for AI agent systems?
RAG is valuable when agents need access to external, domain-specific, or frequently updated knowledge that won't fit in the context window. For simpler or general tasks, it adds unnecessary complexity and token cost—use it only when there is a clear retrieval need.
How do I evaluate whether my context engineering is working in production?
Track metrics like context utilization rate, retrieval precision, and compression ratio. Use probe-based evaluation after compression steps, and watch for context drift signals such as re-reading processed files, restating prior decisions, or gradually reframing tasks.