Introduction
Most enterprise AI teams start their AI journey with prompt engineering — and for good reason. It's fast, accessible, and produces impressive demos. But as AI systems scale into production workflows, something breaks. Teams find themselves rewriting prompts endlessly, outputs stay inconsistent, and the AI that worked brilliantly in testing becomes unreliable when it matters most.
The cost is real. Over 80% of AI projects fail, according to a 2024 RAND Corporation study — a failure rate twice that of non-AI IT initiatives.
Gartner reports that by the end of 2025, at least 50% of generative AI projects were abandoned after proof-of-concept, citing poor data quality, inadequate risk controls, escalating costs, and unclear business value.
The difference between prompt engineering and context engineering determines whether an AI system stays a prototype or becomes a production-grade asset. This article explains why prompt engineering breaks at scale and what context engineering does differently to make enterprise AI dependable.
Key Takeaways
- Prompt engineering crafts effective instructions for single AI interactions
- Context engineering designs the full informational environment around an LLM — memory, retrieved data, tools, and system rules
- Prompt engineering is a subset of context engineering, not the other way around
- Isolated tasks suit prompt engineering; production systems require context engineering
- Using the wrong approach leads to brittle demos, hallucinations, and systems that fail at scale
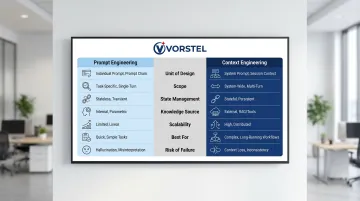
Context Engineering vs. Prompt Engineering: Quick Comparison
| Dimension | Prompt Engineering | Context Engineering |
|---|---|---|
| Unit of Design | Single prompt text | Entire information environment |
| Scope | One input-output pair | Multi-turn workflows, memory, tools |
| State Management | Stateless (fresh each time) | Stateful (persists across sessions) |
| Knowledge Source | Model's trained parameters | External retrieval (RAG), databases, APIs |
| Scalability | Breaks with complexity | Designed for enterprise scale |
| Best For | Demos, one-off tasks | Production systems, multi-step agents |
| Risk of Failure | Linguistic ambiguity | Architectural (missing data, stale retrieval) |
Prompt engineering shapes how the model is asked a question. Context engineering determines what the model actually knows and can access when answering it — a broader, architectural concern.
What Is Prompt Engineering?
Prompt engineering is the practice of crafting precise textual inputs — instructions, examples, role framing, format directives — to guide an LLM toward a desired output within a single interaction window. It focuses on communication quality, not information architecture.
Writing the best possible instruction means adding examples, specifying output format, or framing the model's role ("You are an expert copywriter..."). All of these choices operate inside the prompt boundary — shaping how the model uses what it already sees, not what external data it can reach.
Use Cases of Prompt Engineering
Prompt engineering excels in specific scenarios:
- Exploratory prototyping — testing AI capabilities quickly without infrastructure
- Content generation — writing emails, blog drafts, social media posts
- One-off analysis — summarizing documents, extracting key points
- Copywriting variations — generating multiple versions of ad copy or headlines
- Early-stage demos — showcasing AI potential to stakeholders
Concrete examples:
- "Write me an email in a professional tone requesting a meeting"
- "Summarise this 10-page document in 3 bullet points"
- "Generate 5 product taglines for a sustainable coffee brand"
What these tasks have in common: each one is self-contained. No persistent memory, no external data retrieval, no coordination across multiple steps.
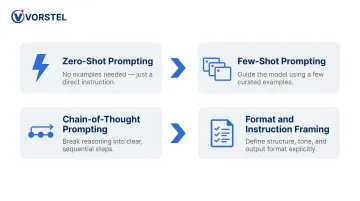
Common Prompt Engineering Techniques
Four major techniques dominate prompt engineering:
- Zero-shot prompting — instruction-only, no examples provided
- Few-shot prompting — adding 2-5 examples to bias the model toward a pattern
- Chain-of-thought prompting — decomposing complex tasks into intermediate reasoning steps
- Format/instruction framing — explicitly stating role, task, constraints, and output format
Each technique refines what the model does with the information in front of it — but none of them expand what information the model can access. That distinction is where context engineering begins.
What Is Context Engineering?
Context engineering is a discipline focused on designing and managing the full informational environment an LLM operates within — shaping what it knows, what it remembers, and what it can act on at any given moment.
One useful frame: if the LLM is the CPU, the context window is RAM. Context engineering determines what gets loaded into that working memory. Anthropic describes it as "the natural progression of prompt engineering" — focused on "curating and maintaining the optimal set of tokens during LLM inference."
What "context" actually includes:
- System instructions — behavioral rules, constraints, tone guidelines
- Conversation and task state — what's been decided, what's still open
- Retrieved external knowledge — documents, APIs, databases via RAG
- Tool outputs — results of executed functions or queries
- Persistent memory — user preferences, domain facts, prior confirmed decisions
Former OpenAI and Tesla AI director Andrej Karpathy endorsed the term in 2025, defining it as "the delicate art and science of filling the context window with just the right information for the next step."
Context Retrieval and Construction
This is the first operational layer of context engineering — acquiring information the LLM needs that isn't baked into its trained parameters. Without it, models hallucinate, pull outdated data, or violate business policies.
Retrieval-Augmented Generation (RAG) serves as the foundation for external knowledge acquisition. Originally introduced by Meta AI researchers in 2020, RAG pulls relevant chunks from documents, databases, or APIs dynamically at query time.
Why this matters:
A 2025 peer-reviewed study tested RAG's impact on GPT-4o accuracy in evidence-based neurology. Results showed document-RAG improved correct answers from 60% to 87% — a 27 percentage point gain. RAG also reduced source fabrication and output variability.
Context Processing and Compression
Raw retrieved information must be transformed before reaching the model. LLMs have finite context windows, and longer contexts degrade reasoning quality.
Research from Stanford University in 2023 found that "performance degrades when models must access relevant information in the middle of long contexts, even for explicitly long-context models." A 2025 follow-up study quantified this: Llama-3.1-70B-Instruct showed a 719% latency increase at 15,000 words of irrelevant context, with operational costs rising sharply despite stable accuracy.
Key processing techniques:
- Summarisation/compression — extract only relevant quotes, discard noise
- Reranking — prioritise the most useful retrieved chunks
- Deduplication — avoid repetition that wastes tokens and confuses the model
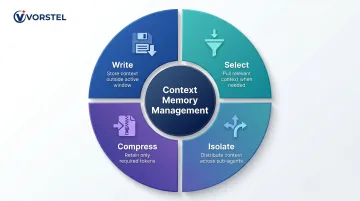
Context Management and Memory
Once context is retrieved and compressed, it needs to persist across turns and sessions. That's where memory comes in. Context engineering distinguishes between:
- Short-term memory — active within one session, persisted in the context window
- Long-term memory — preserved across sessions (user preferences, confirmed decisions, domain facts)
Effective memory requires explicit policies: what gets stored, when it's retrieved, and how it's injected without overwhelming the context window. LangChain frames context engineering around four core strategies:
- Write — save context outside the active window for later use
- Select — pull relevant context back in when needed
- Compress — retain only the tokens required for the current step
- Isolate — split context across sub-agents to avoid overload
Key Differences: What Changes at Enterprise Scale
Failure Modes Shift
Prompt engineering fails at the linguistic level — ambiguity, wrong tone, poor format. Context engineering failures are architectural: missing retrieval pipeline, stale documents, broken tool integration, no memory governance.
At scale, context quality — not prompt quality — becomes the dominant constraint. A perfectly worded prompt is useless if the AI can't access current pricing rules, regional policy variations, or the latest product documentation.
Stateful vs. Stateless
Prompt engineering is inherently stateless — each interaction starts fresh with no memory of what came before. Context engineering is designed for stateful continuity, preserving task history, user preferences, and prior decisions across multiple turns or sessions.
Enterprise scenario: An AI agent managing a multi-step procurement workflow must remember what was approved in step 2 when it reaches step 7. Prompt engineering alone cannot solve this; it requires persistent memory architecture.
Scope: Instruction Card vs. Entire Library
That statefulness difference reflects a deeper gap in scope. Prompt engineering operates within one input-output pair. Context engineering governs the entire information flow:
- Which tools are available to the agent
- How tool outputs re-enter the context window
- What gets retrieved, from where, and when
- What governance rules constrain each decision
Think of it this way: prompt engineering writes the instruction card. Context engineering builds and stocks the library the agent works in.
Scalability
Prompt engineering breaks when user count grows, workflows become multi-step, or domain-specific knowledge is required. Teams end up "stuffing" more text into prompts, creating brittle, drift-prone systems.
Context engineering is built for scale from the start. Retrieval pipelines, persistent memory, and tool orchestration handle growing volume and complexity without requiring manual adjustments per interaction.
Debugging and Governance
When a prompt-only system fails, the fix is rewording. When a context-engineered system fails, there is a traceable architecture to inspect: retrieval logs, tool call records, and memory states.
This auditability matters for enterprise AI governance. Two major frameworks make it a requirement:
- EU AI Act Article 13 requires high-risk AI systems to be "sufficiently transparent to enable deployers to interpret a system's output."
- NIST AI Risk Management Framework mandates explainability and incident logging for trustworthy AI deployment.
Context-engineered systems produce the audit trails these frameworks demand. Prompt-only systems don't.
When Prompt Engineering Falls Short: Enterprise Failure Modes
Prompt engineering makes three core assumptions that break in enterprise environments:
- All relevant information fits in one prompt
- Each interaction is independent
- The user manually provides the right context every time
As systems grow, all three assumptions fail. Gartner's 2025 data readiness report found that 63% of organizations either do not have or are unsure if they have the right data management practices for AI. The RAND Corporation's 2024 study identifies "lack of data" as a leading root cause of AI failure, noting: "80% of AI is the dirty work of data engineering."
Enterprise scenario:
An AI assistant deployed in an ERP or CRM environment (SAP, Salesforce, Microsoft Dynamics) gives wrong answers because it cannot access current pricing rules, regional policy variations, or the latest product documentation. No matter how well the prompt is written, the AI fails because it lacks the right context.
This is where organizations in manufacturing, retail, and e-commerce feel the most pain. AI tools that can't account for live operational data produce unreliable outputs — and no amount of prompt refinement fixes a missing data layer.
These scenarios aren't edge cases. They reflect a consistent set of failure modes that emerge as AI deployments scale:
Common failure modes at scale:
- Prompt bloat — teams keep adding context directly to prompts, making them longer, fragile, and hard to maintain
- Instruction drift — repeated instructions producing inconsistent behavior across sessions
- Lost continuity — no memory of prior interactions means users restart from scratch every time
- Auditability gap — no way to explain why the model answered a specific way

When to Use Prompt Engineering vs. Context Engineering
Both approaches belong in any serious AI build — prompt engineering is a subset of context engineering, not a competitor to it. What matters is knowing which deserves the heavier investment at your current stage.
Choose prompt engineering as primary focus when:
- Tasks are isolated and one-off with no multi-turn requirements
- Early-stage prototyping or demos
- Content generation where the model's trained knowledge is sufficient
- Single user, no personalisation needs
Invest in context engineering when:
- Multi-step or multi-turn workflows (AI agents, agentic pipelines)
- Systems that depend on real-time, domain-specific, or proprietary data — customer support bots, internal knowledge bases, ERP-integrated assistants
- Systems requiring auditability, governance, or compliance traceability
- Production systems deployed to many users at scale
A reliable signal you've crossed that threshold: your AI works in demos but degrades in production — and every fix involves stuffing more into the prompt. At that point, context engineering isn't optional; it's the missing infrastructure layer.
Conclusion
Prompt engineering and context engineering are not competing disciplines — they operate at different layers of the same system. Prompt engineering is effective for shaping how the model communicates; context engineering determines what the model knows and can act on.
Enterprises that conflate the two spend months refining prompts for problems that are fundamentally architectural. The organizations that successfully move from demo-grade to production-grade AI treat context as a designed system — not an afterthought.
Getting this architecture right from the start translates directly to faster deployment cycles, fewer hallucinations in live systems, and AI that can actually be trusted at scale. Vorstel Technologies helps enterprises get this foundation right — from AI strategy through implementation — whether that means integrating AI into existing SAP environments, Salesforce workflows, or custom software platforms. The goal is the same: AI systems that run on accurate, governed, and relevant information at every stage of deployment.
Frequently Asked Questions
Is prompt engineering still relevant if I'm doing context engineering?
Yes, prompt engineering remains important — it is a core component of context engineering. The difference is that in mature systems, prompts are designed, constrained, and injected as part of a broader context strategy rather than used in isolation.
Is prompt engineering a subset of context engineering?
Yes, prompt engineering is a subset of context engineering, not the other way around. Context engineering governs everything the model sees before generating a response, and the prompt is one element within that larger system.
What are common context engineering techniques used in enterprise AI?
Key techniques include:
- Retrieval-Augmented Generation (RAG) for external knowledge access
- Context compression and reranking to manage token limits
- Short- and long-term memory management
- Tool orchestration with defined permissions
- Structured system instructions
How does RAG relate to context engineering?
RAG (Retrieval-Augmented Generation) is a core implementation component of context engineering. It allows AI systems to dynamically retrieve relevant, up-to-date information from external sources rather than relying solely on what the model learned during training.
What happens when context engineering is done poorly?
Poor context engineering leads to system-level failures: the model forgets its goals, retrieves wrong or stale information, misuses tools, or produces inconsistent and unauditable outputs — issues that cannot be fixed by improving the prompt alone.
Can prompt engineering alone support a production enterprise AI system?
For simple or isolated tasks, prompt engineering can be sufficient. However, for any production system involving multi-turn interactions, proprietary data, user-specific personalization, or governance requirements, context engineering is required to make the system reliable and scalable.